
研究了四个多月AI绘画,又把ChatGPT作为日常工具用了一个多月后,忽然有点明白特德·姜那篇《ChatGPT是互联网的一张模糊JPEG图像》背后的含义了。
因为AI目前的训练集只不过是512×512到768×768分辨率的图片,而各种附加的、混合的、额外训练的模型,受限于算力,也无法从根本上提升它的精度。
你看到的AI成品越精美,其实代表它越接近于原始训练集,换言之就是过拟合了。
如果试图单靠AI画出一张细节尽可能完美的图,结果往往会令人沮丧。例如只有一只手不完美时,理论上我们可以用Inpaint单独重画,但很可能几百轮重画下来都未必能达到想要的结果。全图重画又可能顾此失彼,手完美了,别处又乱掉了。
这几乎是“精度不足”现状下的必然情况。区区数GB的基础模型和消费级显卡,在可接受时间内能生成的极限就是如此。
能精准控制绘画结果的Controlnet发布后令人精神一振,正说明了AI绘画至今困扰我们的局限所在:不借助人力进行强力干预的情况下,单靠AI画出理想的作品难如登天。
绘画和ChatGPT、还有精度有什么关系呢?
同为AI,同样基于神经网络,底层终究会遇到同样的问题。
我们尚不清楚背后的GPT 3.5模型究竟有多大规模。但想想就知道,无论如何都会比它吸收学习的整个互联网和人类知识总和要小得多得多得多,至少有几个数量级的差距。
在咨询一些笼统概念、文本写作时,ChatGPT会给出很漂亮的结果。
而一旦你寻根究底,试图让它在细节也尽善尽美,就会出现哭笑不得的结论。
前些天我在微博看到小学的数学题,很简单,打算塞给ChatGPT问问。
只要学过九九乘法表,对里面的数字就会有直觉,然后得出结果。
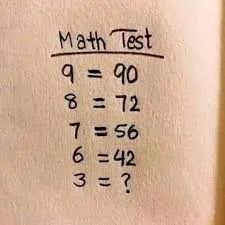
当然,ChatGPT没有这种直觉,但它也能找出其中的规律:

令人疑惑的是,尽管它换了种方式来总结规律,而且规律是正确的。但最后的答案却是失了智一样。
后来对话反反复复进行了好多次,无论我如何引导,它只会不停道歉然后再次装模作样地分析,得出再一个不同的错误答案。
这时候心累的我脑中忽然闪过一个场景,就是此前在调教AI绘画时,那个反复无数次也画不好的手指:
它的精度已经到极限了,再精妙的算法也没法从单个像素还原出一幅图,或者从单个数字还原出一本数学书。
而且,这种精度不足不仅仅出现在数理问题上,人文历史方面只要不停追问细节,一样会最终崩溃掉。
随便举个例子。我很早前问过它一个知识性问题:乾隆年间为何中国人口迅速增长。
它回答了四个原因,包括粮食增长、健康医疗、战乱减少、人口流动。当然每条还包括了一些解释。
然后我追问粮食为何增长,它回答农业技术、水利、土地制度、外贸等。
我再追问农业技术有哪些,它回答引进种子、灌溉、耕作、动物饲养等。
继续追问具体哪些种子,它抓瞎了,只能承认自己不清楚,但声称据记载还是引进了许多农作物和动物的。
再问哪些农作物和动物,精彩的来了,它居然直接告诉我,引进了棉花、花生、甘蔗、番茄,甚至马、牛、羊、猪。
这时候按说它已经崩溃了。反问一句,这些真的都是乾隆年间引进的吗?它就开始说,其实不是的,有的是唐朝,有的是明朝,跟上一句已经开始前后矛盾。
再问下去没有更多意义,无非是精度触底后在说车轱辘话而已。
恐怕大家最近在网上见过很多ChatGPT的搞笑答案,其实相当一部分,就是AI在极限精度下随机冒出的胡话。
也正是因为如此,ChatGPT和new Bing能漂亮高效解决我们生活工作中的一些问题,却解决不了另一些细节更多的问题。
而更沮丧的是,中文互联网内容质量的低下和封闭,最终导致中文部分在这张JPEG图里会“更模糊”一些。
有可能即将到来的GPT-4会大力出奇迹,靠高出几个数量级的训练集再次突破我们的想象力;或者在当前模型体系下触碰到了AI自身的算力极限,发现它也只是一张分辨率更高而放大后同样模糊的JPEG图片……
补充个例外:ChatGPT能生成可直接运行的程序代码,这不是因为程序的精度要求低,而是OpenAI背后专门有细分模型(Codex,最新版本代号code-davinci-002)针对代码生成做了海量学习。你可以想象成如果AI专门用几千万张人手图片特训过模型后画出的手必然不会是现在这个样子。
(注:题图是用“ChatGPT Is a Blurry JPEG of the Web”为关键词让AI画的)
用ChatGPT你现在再去问那个问题在第二次问的时候答案就正确了。我觉得精度只是时间问题……